
Rapid evolution and advancement of technology demand federal agencies adapt, shift, and change their data strategies or plans of action. Embracing disruption is key to recognizing and implementing these transforming technologies. The latest industry trend is to utilize the vast amount of data and turn it into actionable insight. While some agencies use data for simple reporting and analytics, others unleash greater potential by applying AI and machine learning (ML) technologies.
While we all know the value of data, some of the biggest mistakes an agency can face can be prevented with diligent data preparation. Intelligently predicting an outcome, preventing waste, or streamlining a process can all be done by utilizing data; however, these processes get delayed when siloed systems, incorrect formatting, and purposeless collection bog down the design.
The latest advances in machine learning operations (MLOps) have created viable processes to engineer and utilize data in new and unique ways, such as using satellite imagery data to predict natural disasters, or data mining techniques to identify threats to national security. These various data use techniques provide outcomes that can help view the progression of a project, glimpse into the future, and what steps can or should be taken next, all of which support critical decision making. Toward that end, prepared, conditioned, and ready-made data are key to successful mission operations and outcomes.
Three tenets to effective data engineering
At NT Concepts, we take a disciplined and practical approach to data management, aligned with best practices, including those found in the DoD Data Strategy. This approach is increasingly important when using data collection to bolster strategic capabilities for operations in the field in addition to internal agency decisions.
There are three tenets to effective data engineering:
- making data discoverable and reliable,
- keeping data accessible, and
- utilizing contextualized intelligible data.
There are various goals and objectives set by the government to abide by these tenets. The goal of the first tenet, data discovery, is to find what is of value to the organizations’ interest and to streamline this process. A good objective of the DoD is to implement common services to publish, search, and discover data.
The second tenet, keeping data accessible, can complicate things. Regarding the DoD, organizations must comply with Public Law (P.L.) 115-435, the Foundations for Evidence-Based Policymaking Act of 2018.1 Within the Intelligence Community, there are multiple standards for organizations to follow, like the ISO Information Security Standard – 27001.2 As a result, security controls must be put in place, especially when making war fighting and intelligence data accessible to authorized users. There are various levels of data available to these authorized users, which creates an enhanced need for streamlined processes and checklists to ensure the proper data access is given.
Lastly, intelligible data must be trustworthy to deliver the needed value to various service members, civilians, and stakeholders, resulting in well-timed, thought-out decisions.
All three tenets enable organizations to work with easy-to-obtain and accurate data readily turned into viable information. Yet, as we all know, data rarely come prepared—it is quite the opposite. According to the International Data Corporation (IDC), 80% of worldwide data will be unstructured by 20253, meaning the data lack a pre-defined ontology or data model. This unstructured data provides very little value to decision-makers because of its inability to fit into a machine learning or statistical model. Data are constantly generated and by themselves mean nothing. However, the data can come together like puzzle pieces to tell a story.
Here is where data readiness comes into play.
How to discuss data
One of the biggest challenges when talking about data readiness is that it is an abstract concept. While developers and scientists who work with data regularly understand how “prepared” data should look, it can be challenging to convey that same understanding to stakeholders. This confusion happens because data are treated as an idea and not valuable assets.
In practice, referring to something as “big data” is like referring to a power grid as “big electricity” or managing a series of factories as “big manufacturing”; they are helpful as broad concepts but difficult to tie to something specific and actionable. This nebulousness leads to poor data readiness—it is hard to improve on something indistinct. Put another way, even if some people at an organization know more about the data than the raw information that resides in a data store (e.g., the context, the provenance, the reliability), when it comes to consuming the data in a model or analytic, that additional knowledge is unreachable. The data consumed are just what is stored; it is critical to capture that extra knowledge to something explicit that lives in the data repository.
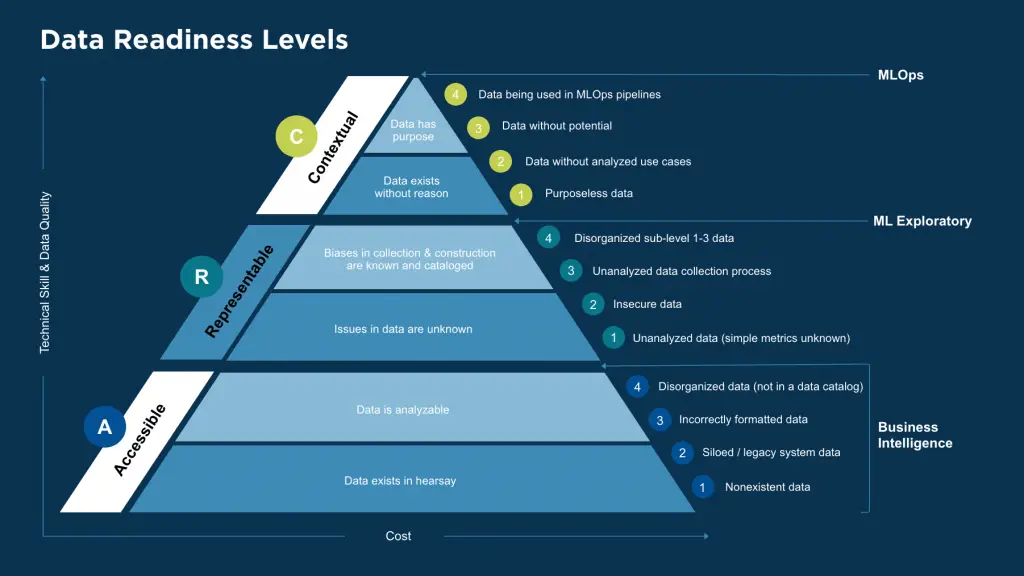
As shown in Figure 1, Data Readiness Levels (DRLs) are a systematic way to combat poor data preparation and representation.
The levels have the primary objectives of understandability and generality. Ideally, the system should be mountable to any workflow and adaptable to any business case, with goals specific enough to bring genuine improvement to generatable data.
DRLs are best expressed as a pyramid. Each letter represents a new level of data readiness: Accessibility, Representability, and Context. Each level can be further divided into sub-levels to make the targets even more specific. Here we will speak to four sub-levels, but the format is flexible. The goal is to move from the bottom level, A1 (Accessibility) to the top C4 (Context), enriching or conditioning the data as necessary along the way. Another benefit of the pyramid shape is distinguishing what kind of effort goes into each level. At the lowest level, the time and effort to establish good practices will be expensive but require the fewest data professionals for implementation. As you move up, the necessary expense goes down, but the level of skill in data product creation needed to progress into new levels goes up. For example, data are ready for MLOps only after achieving level C4.
Traditional conversations on improving data readiness are couched in technical language by necessity. For instance, a common goal might be to operationalize a legacy database by moving the structure to a cloud system, with no visible changes to the database users. This can be a valuable undertaking, but an explanation of the value is locked behind a baseline fluency in data.
Contrast this to a typical DRLs conversation: A legacy database might be at level A2, where data exists and are accessible in some cases, but not to everyone who can use them effectively. The goal of moving to the cloud is an issue of moving the data from A to R—meaning accessibility problems are virtually solved.
Understanding why a database should be migrated to the cloud is unnecessary in the second conversation and refocuses priorities to concepts instead of technologies—what is important is not the migration itself; it is the solving of accessibility issues. Similar sentiments can be expressed as agency goals: “We would like to see our data move from R to C this year” or “What level of readiness is our current data?” require little technical fluency compared to their counterparts, despite having a technical underpinning.
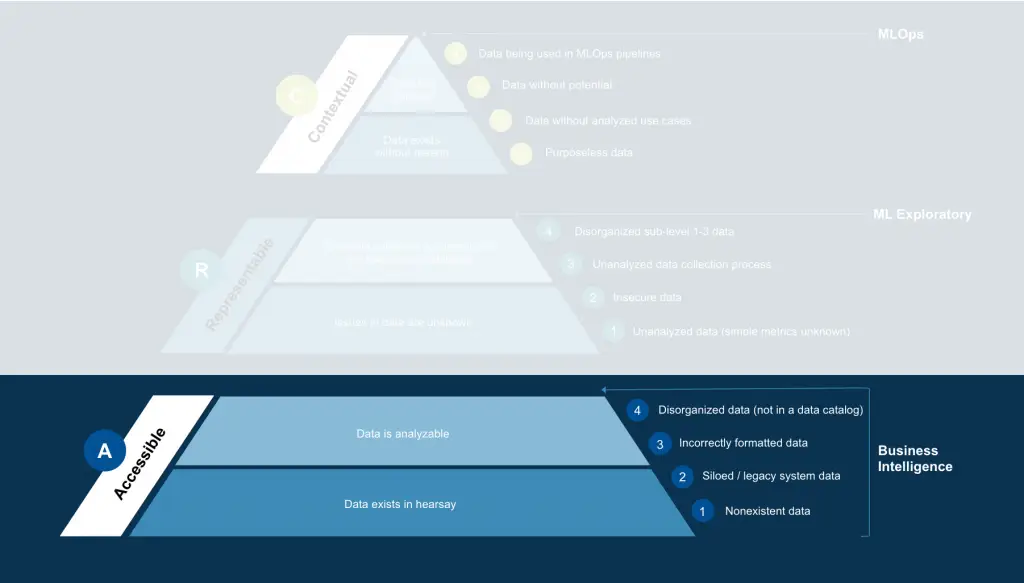
Accessibility
While there is undoubtedly much to be said about the implementation of Accessibility in data, general concepts can help ground an idealized conversation among technical staff. At A4, the lowest level in data readiness, is an acknowledgment of a need for data and proper organization. Data are still “hearsay” at this stage, meaning the data should be available in some format. This lack of understanding of whether the data are available, and furthermore how to access them, is a demonstration of severe inaccessibility. In some cases, there are no such data. More often, the issue stems from disorganization. For example, data could be unmaintained in legacy systems or departmentally siloed. In others, systems store structurally identical data in disparate organizations, leading to duplicate and incomplete records.
Datasets are meant to be a collection of usable knowledge, and inaccessible data, such as is found in legacy or siloed systems, is unusable. Conversations in the early stages of A primarily consist of porting to a modern infrastructure, such as cloud platforms, or transformation to formatting ready for business intelligence (BI), such as OCR correction for scanned documents, or movement to computer-native documents altogether. Moving completely from A4 to A1 means taking these data and transforming them into the form consumed by BI tools in addition to addressing fundamental data storage issues. It is mandatory these steps be taken before production-level ML can be implemented. Building the infrastructure to support this can be an endeavor, and as such, is associated with a considerable resource cost.
Here is also the time to consider privacy and information security: Who can access the data and when? What information needs censoring? Does the collection of information conform to current laws and clearance standards? These questions can all become severe problems without proper consideration in advance.
Once the data achieves A1, there should be a thorough system in place to easily access data, including a data catalog for indexing data sources. This improvement significantly increases the efficiency of common BI tasks and lowers the effort to wrangle data. The organization can then graduate to the next task of Representability.
Representability
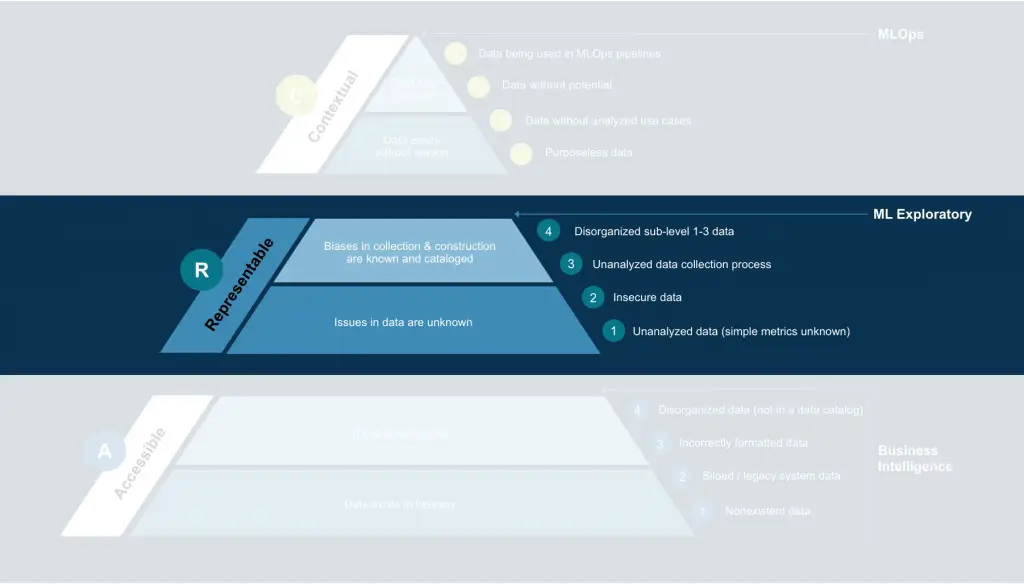
We represent DRLs as a pyramid because every step builds on each other. A solid structure for answering Accessibility will help address the problems and questions that can arise when speaking on Representability.
Representability in data is a focus on two major factors. The first is exploratory data analysis. There should be analytical insurance that there are no fundamental issues with the dataset being recorded. While this may seem to be common sense, sanity checks are more important than usually considered. A famous example of this is conversion errors, such as in the Mars Orbital4, where commands were issued in Imperial to an onboard sensor using Metric, leading to the orbiter disintegrating into the atmosphere.
Other, less catastrophic issues may be a high covariance between columns, a minority-majority class imbalance, high missingness, or any number of other data-related issues. If possible, these should be fixed in the data collection infrastructure created in A; however, simple awareness and (more importantly) cataloging of these issues will generate expedience during MLOps. While many of these problems can have solutions, learning the problem can occasionally benefit an ML algorithm. The decision should be left to data scientists on a case-to-case basis. This understanding of what problems are catastrophic and what problems should be left for C-level development requires a higher level of data knowledge than A-level.
The other primary factor to address in Representability is bias, specifically collection bias. For example, it is critical to have a diverse range of people represented in dataset creation in face or speech recognition systems, as models regress towards majority classes leading to difficulties achieving high accuracy on minority classes. Basing decisions on a model with collection bias could be disastrous. This can be another fundamental flaw of the design of the infrastructure created in A-level. In this case, developers must create new infrastructure to increase to a higher tier. However, there are also techniques to address this after the data is collected. More often, being aware of these issues is helpful enough for data operations.
As previously stated, a higher level of data knowledge is required in R than in A – however, the actual diagnosis of issues requires far less development. The results of an exploratory data analysis are all that is needed to examine what problems are occurring. As the data infrastructure created in A-level can support common BI tools, creating this analysis will be expedient compared to teams not practicing data readiness. This tends to be a smaller lift than infrastructure creation. The sample visualizations created from the exploration should be saved in the data catalog, along with any major problems with the dataset, for reference by data scientists in C-level.
The data are now ready for ML Research.
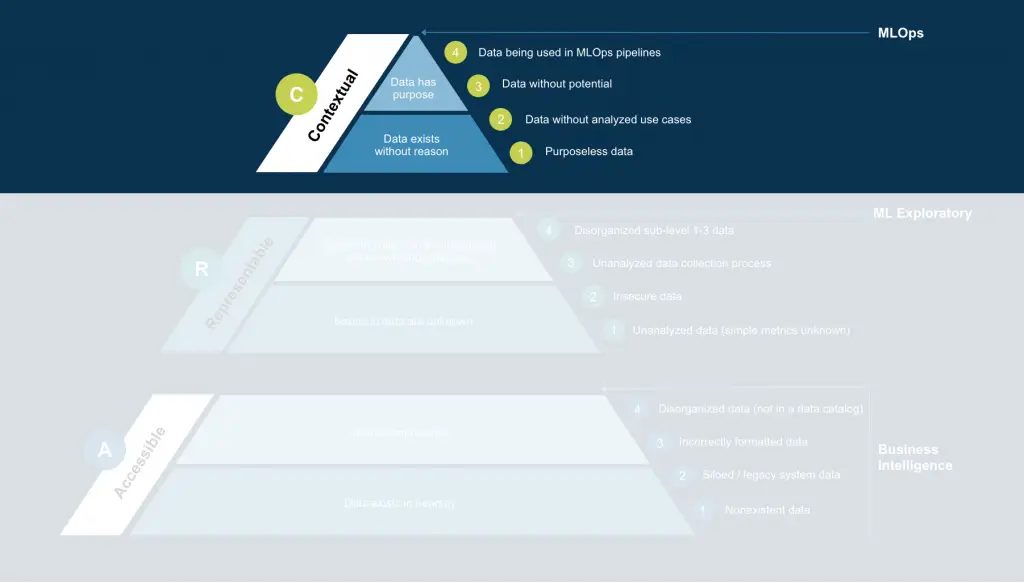
Context
Context is the highest tier of data readiness. While it is the least intensive development step, it also requires the highest level of data expertise. After completion of R-level, a data catalog is segmented across dataset lines, and while knowledge itself has organization value, learning systems and data mining can cause that value to exponentially increase. The role of a data scientist is to understand both the correct tools to process data for increased value and the connections between disparate data sources. In conjunction, data scientists bring value by predicting system failures, recommending action courses, and numerous other hook-based execution strategies.
The goal for a data scientist concerned with context is how to explain what questions data answers through its collection and analysis. For instance, logging user activity in a system helps answer what activity is anomalous and how much of a threat the behavior is. Another example may be the collection of employee resumes, which can help build better job listings for various positions. The goal is to take what is already collected and provide purpose for it.
Machine learning can be treated as the end of the data readiness process, although it is not always needed for action. While predictive tools are excellent, they are not always needed depending on the question the data asks. Understanding the various models and tools in play for contextual analysis is a research-heavy, development-light process founded on prior knowledge, which is what allows level C to have the highest level of data expertise and the lowest level of development needed.
Conclusion
The use of well-engineered data has grown exponentially as technology continues to evolve. As agencies collect greater amounts of data, the more questions they need answers to. AI/ML is at the forefront of data and the latest trend in streamlining business processes to answer these questions. Engineering a sound ML model with a solid MLOps core for standardization and delivery gives organizations immediate operational advantage and increased efficiency.
The process of creating these models takes time, skill, and resources that must be utilized properly for a beneficial outcome. The first step is to engineer ready-made data using the DRLs, and the next is to create operationalized ML models to use that gold standard data to produce intelligible, actionable insight.
References
1 https://media.defense.gov/2020/Oct/08/2002514180/-1/-1/0/DOD-DATA-STRATEGY.PDF
2 https://www.insightsassociation.org/get-support/iso-information-security-standard-27001
3 https://www.ibm.com/blogs/journey-to-ai/2020/11/managing-unstructured-data/
4 https://solarsystem.nasa.gov/missions/mars-climate-orbiter/in-depth/

