
This article is part two in a series on data management focusing on cloud, hybrid cloud, and community cloud for our government customers working to derive more value at scale and increased speed from their data operations.
The business case for going cloud native
Organizations that choose to completely migrate data repositories to a cloud service provider such as Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and Oracle Cloud Infrastructure (OCI) have excellent cloud-native data management services and platform options.
In this article, we dig below the hype cycles and buzzwords to understand the challenges of effectively using data and protecting access to it. As stated in our previous article, when organizations use cloud service providers, the data challenge becomes more apparent. Simply lifting-and-shifting data stores to a cloud provider without having a data management plan and appropriate cloud technical skills will lead to a decrease in the original forecasted Return-on-Investment (ROI) and loss of opportunity to use the data effectively (e.g., opportunity cost).
Many ROI estimates for cloud-native solutions—including cloud data management services— are based on cost-saving assumptions such as:
- Reduced IT staffing (e.g., using Terraform & native infrastructure-as-code tools)
- Lowered upfront capitol expenses into equipment and licensing costs (e.g., using AWS/Azure Spot instances, managed services, and native SaaS and PaaS)
- Data lifecycle management tools and automated data-tiering and tagging (e.g., using data storage, and native ingest and data curation services)
Gain organizational agility with data management
Chief Information Officers (CIOs) must deliver efficient IT solutions and data management differentiators to remain competitive. Executives and leaders are realizing the IT department as a competitive enabler through unlocking advanced analytics, machine learning, and artificial intelligence. Many CIOs and Chief Data/Digital and Analytics Officers (CDAOs) can find cloud-native solutions such as adopting data lake and data lakehouse architectures as reasonable foundational data governance technologies.
Additionally, some organizations are shifting from Chief Data Officers (CDOs) to CDAO positions to recognize the analytics domain required for data management efforts. Earlier this year, the Department of Defense (DoD) announced Dr. Craig Martell as its first CDAO, showing their recognition and commitment to becoming a data-centric organization within the federal government. At the 2022 Intelligence & National Security Summit, Dr. Martell stated data storage and infrastructure “shouldn’t be centralized.”
The CDAO’s sentiments would indicate creating a data mesh integrated with the emerging data fabric already being developed for efforts such as the Joint All Domain Command and Control (JADC2), which focuses on data-driven decision support for Mission Command.
There are challenges with only leveraging central data teams as identified by Google, for example, when only using data fabric design patterns:
“...as your data teams attempt to work in a centralized data model, they might rely on a central IT team to incorporate new data sources. This causes delays in deriving insights from data and results in stale data when pipelines are not kept up to date.” 1
Common failure modes using only data lake or lakehouse architecture
As shown in Figure 1 below, the bottleneck of a central data team is one of the primary “failure modes” identified by Zhamak Dehghani. In her 2019 article, “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh,”2 Dehghani explains data mesh design patterns and the need for them. By disaggregating data product creation and allowing functional area data stewards to use their own departments’ domain-driven expertise, and organization can accelerate building data products that generate agility and enhance competitive advantages. These data products may be machine learning (ML) models, inputs to artificial intelligence (AI) systems and components, or curated datasets used in other analytics and data products.

Figure 1. Enterprise IT Bottleneck. Centralized teams operate in a resource-constrained environment, limited by factors including time, funding, and data domain expertise. Prioritization becomes a competition and slows data product teams.
Data Management Goals from the DoD Data Strategy
The DoD Data Management goals primarily focus on the data consumer and require a Data Strategy Implementation Plan (DSIP). NT Concepts specializes in developing and actioning these plans for our DoD and Intelligence Community customers using both cloud-agnostic and cloud-native service offerings that fit an organization’s risk appetite and goals.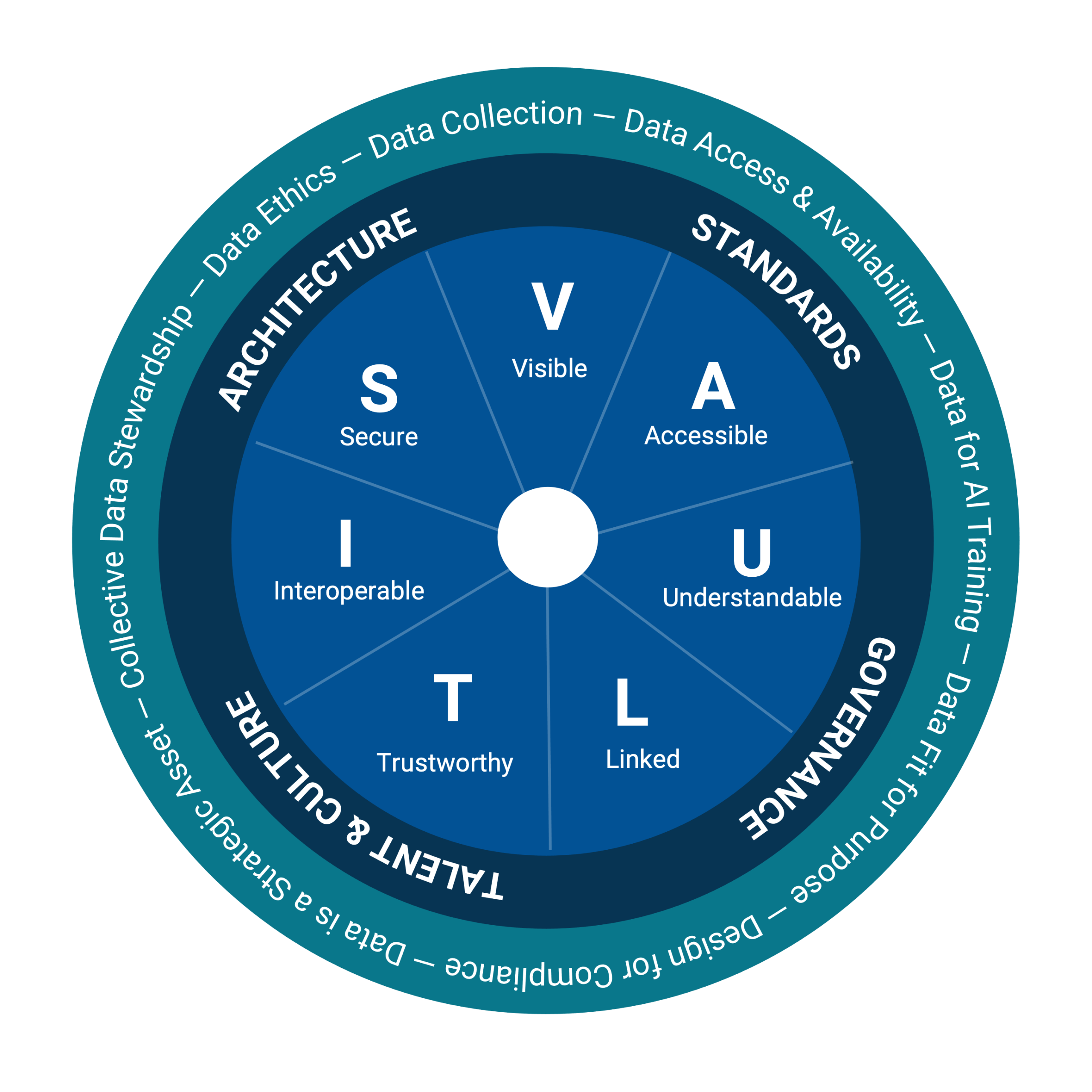
VAULTIS Acronym:
- Make Data Visible – Consumers can locate the needed data.
- Make Data Accessible – Consumers can retrieve the data.
- Make Data Understandable – Consumers can recognize the content, context, and applicability.
- Make Data Linked – Consumers can exploit data elements through innate relationships.
- Make Data Trustworthy – Consumers can be confident in all aspects of data for decision-making.
- Make Data Interoperable – Consumers have a common representation/ comprehension of data.
- Make Data Secure – Consumers know that data is protected from unauthorized use/manipulation.
Data mesh cloud–native services
Data mesh is a design pattern that drives data architecture decisions to local data authorities with data ownership. This decentralized data management design has more flexibility for data governance than approaches centralized data teams use in the data fabric design pattern, allowing data product decisions at the mission or departmental level (however, data is still enrolled to the central data catalog).
Both data mesh and data fabric use semantic knowledge graphs to enable searchability across distributed data repositories—regardless of where they are stored. As noted in the previous article, the data mesh design pattern requires:
- Data teams to be purpose-built around the data products they want to create
- Disaggregation of data product decisions to departments increasing flexibility
The trade-off is that this approach increases personnel costs while increasing data product creation value. These data product teams are decentralized and require a data product owner, data engineers, software engineers, and a product manager, depending on size per department.
Data mesh platforms are primarily built using cloud-native offerings deeply integrated into specific cloud vendor services, which may be interoperable with other providers but require application gateways and refactoring of data products from one vendor to another. However, not every cloud service offering is currently DoD FedRAMP-approved for sensitive workloads.
Cloud–native data mesh design patterns and cloud service offerings
Below are 2022 cloud-native data mesh design patterns and cloud service offerings that we help our customers design, build, and sustain. NT Concepts can help your organization ask the right questions to mission owners relating to data management, MLOps, digital engineering, and cloud to find the best solutions for your unique needs.
Data mesh AWS services
AWS data mesh design pattern starts with building an initial lakehouse architecture using AWS Lake Formation service for centralized data management policy creation and AWS cross-account governance using automated repeatable templated playbooks built-in that make use of other complicated AWS services such as AWS Organizations, AWS Glue, AWS Identity and Access Management (IAM) with ease. AWS Lake Formation is at the center of building, scaling, and managing a data mesh in AWS. Figure 2 is a conceptual overview of what capabilities AWS Lake Formation provides for data management.
The next step after enabling the AWS Lake Formation service to create the data management policies and guardrails is to create a unified data management control plane using AWS Glue services to crawl, discover, and register data sources, schemas, and metadata.
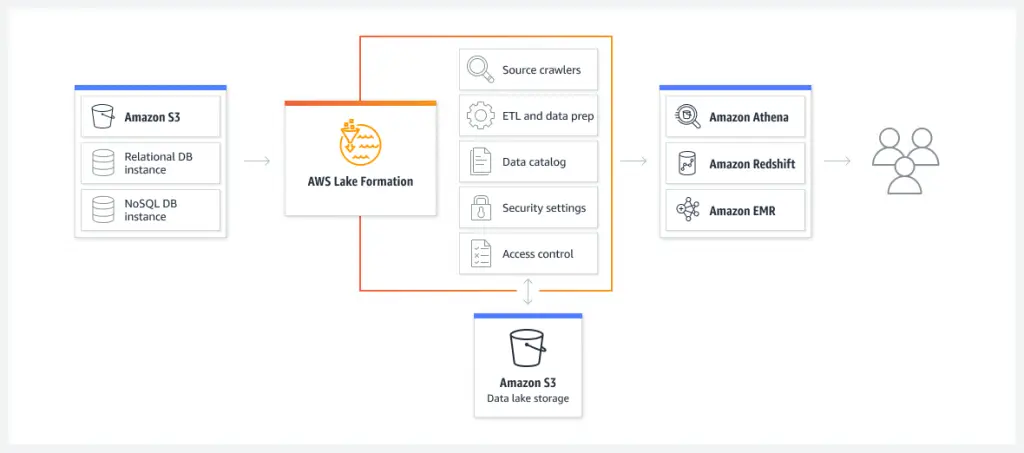
Data management and governance using AWS data mesh design
- AWS Lake Formation for data stewards, data custodians, and data managers to develop data management policies and enforce governance
- AWS Glue Data Catalog to register the metadata catalog and searchability
- AWS Glue Schema Registry to discover and control data stream schemas
Data ingestion
- AWS Kinesis for streaming data sources
- AWS SQS for asynchronous batch data
- AWS Data Pipeline to build ETL Pipelines
- AWS Data Migration Service to migrate databases
Data storage
- AWS S3 for blob data for any file type or schema/unstructured data
- AWS RedShift Spectrum Oracle SQL alternative – structured/relational
- AWS RDS for managed or self-hosted SQL – structured/relational
- AWS Aurora for managed MySQL, PostgreSQL for open-source structured/relational database alternatives
- AWS DynamoDB for key/value pair managed NoSQL (Not Only SQL)
- AWS EC2 for virtual machine-based self-hosted databases
Data enrichment
- AWS Glue Studio GUI Apache Spark ETL Jobs
- AWS Glue ETL to read and write metadata to the Glue Data Catalog
- AWS Glue DataBrew to visually create, run, and monitor ETL jobs
Data processing and analytics
- AWS Glue for data engineers and data managers to manage data sources
- AWS Athena for data engineers to use SQL on S3
- AWS SageMaker Data Wrangler for data scientists supporting data-readiness and data maturity requirements
- AWS Databricks for managed collaborative workspace for data scientists
Data serving
- AWS RStudio SageMaker for data scientists conducting statistical analysis
- AWS Quicksight (data engineer/business analyst)
- AWS EMR Studio (data analyst)
- AWS Kinesis Video Streams (OSINT analyst)
Data mesh Microsoft Azure services
Microsoft Azure data mesh design pattern starts with the adoption of Cloud-scale analytics, a framework to deploy reference architectures. These reference architectures are defined in Infrastructure-as-Code (IaC) that is developed and maintained by Microsoft Azure Experts.
The initial deployment templates to run are Data Management Landing Zones (LZ) and Data Landing Zones. Azure builds upon these Data Management LZs and Data LZs using Microsoft Purview to create a data mapping of data source repositories, build a data catalog, share data, and enable some components of data rights management (DRM) from the DoD Zero Trust Reference Architecture v.2.0. Figure 3 is an overview drawing (OV-1) of how Microsoft Purview integrates with other Azure-native data management services.
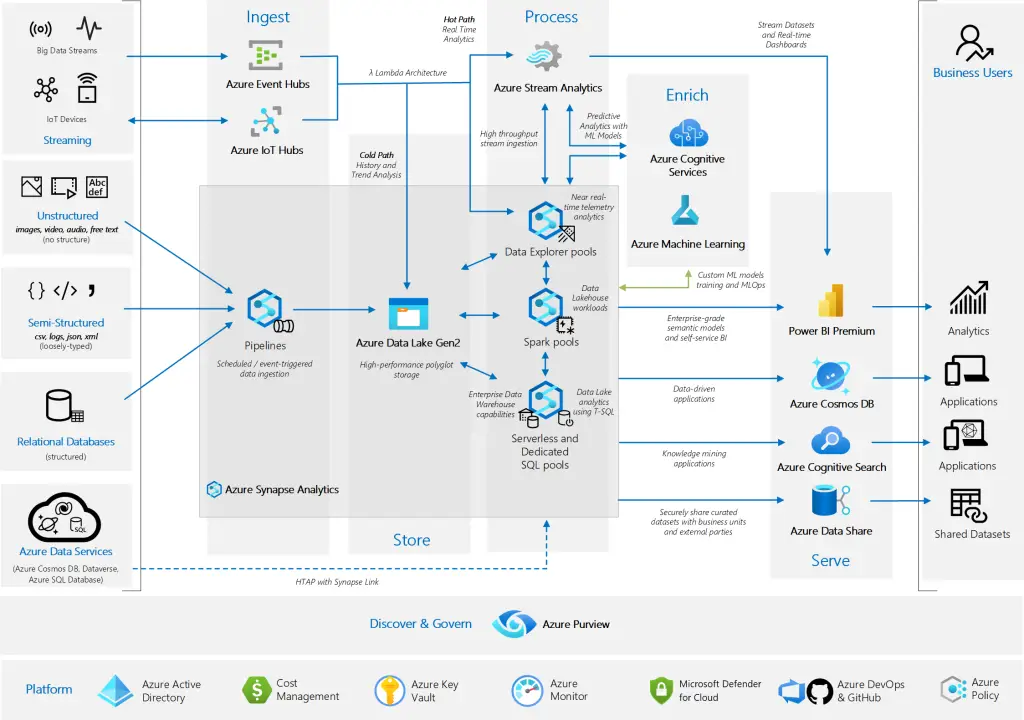
Data management and governance using Azure data mesh design
- Microsoft Purview for data stewards, data custodians, data managers to develop data management policies and enforce governance
Data ingestion
- Azure Event Hub for real-time and streaming data sources
- Azure IoT Hub for edge device data sources
- Azure Data Factory for ingest and ETL of data from an Azure storage repository
Data storage
- Azure DataLake Gen2 to create data lake repositories
- Azure SQL Server
Data enrichment
- Azure Cognitive Services for predictive analytics with ML models
- Azure Machine Learning for custom ML models training and MLOps
Data processing and analytics
- Azure Stream Analytics to recognize patterns and relationships in data for many use-cases
- Azure Synapse Analytics to search or query your data sources
- Data Explorer pools
- Spark pools
- Serverless and Dedicated SQL pools
- Azure DataBricks for managed collaborative workspace for data scientists
Data serving
- Azure PowerBI Premium for semantic models and self-service BI
- Azure Cosmos DB for data driven applications
- Azure Cognitive Search for knowledge mining applications
- Azure Data Share to securely share curated datasets
Data mesh GCP services
GCP data mesh design starts with using GCP DataPlex unified data management service. Figure 4 shows how GCP DataPlex governs other tightly integrated services in GCP and other cloud provider data repository services. Along with data management, Google wants data to be discoverable via a data marketplace, where data producers can publish datasets for others to consume using the Data Catalog within DataPlex.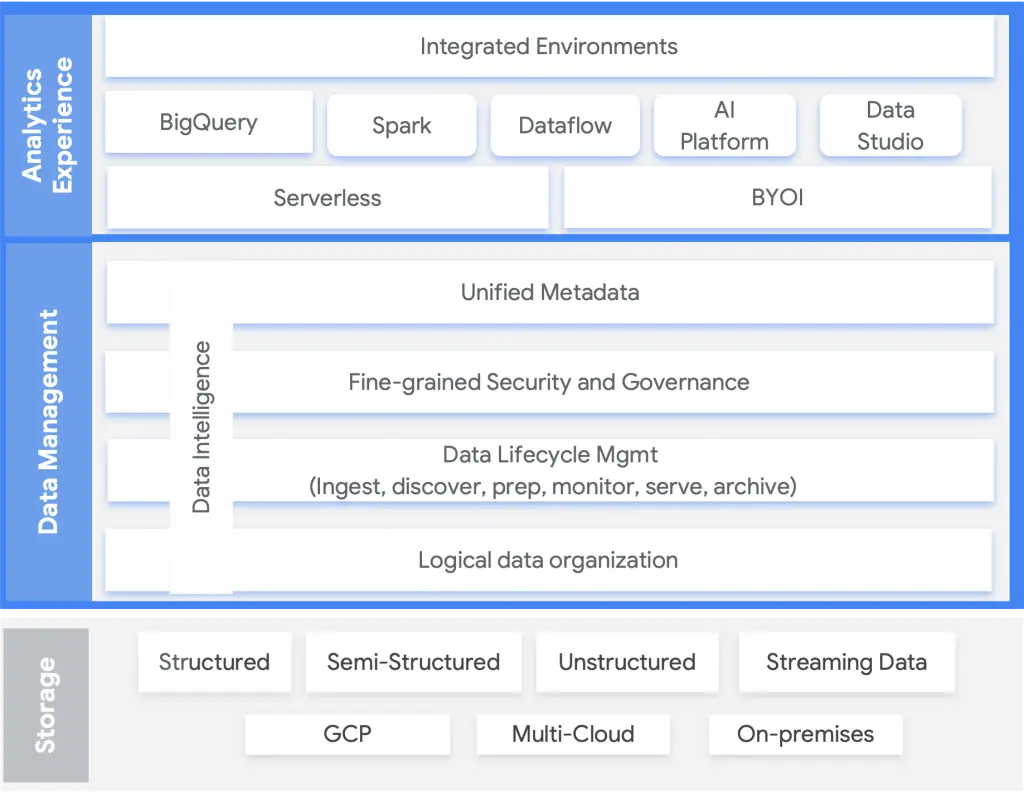
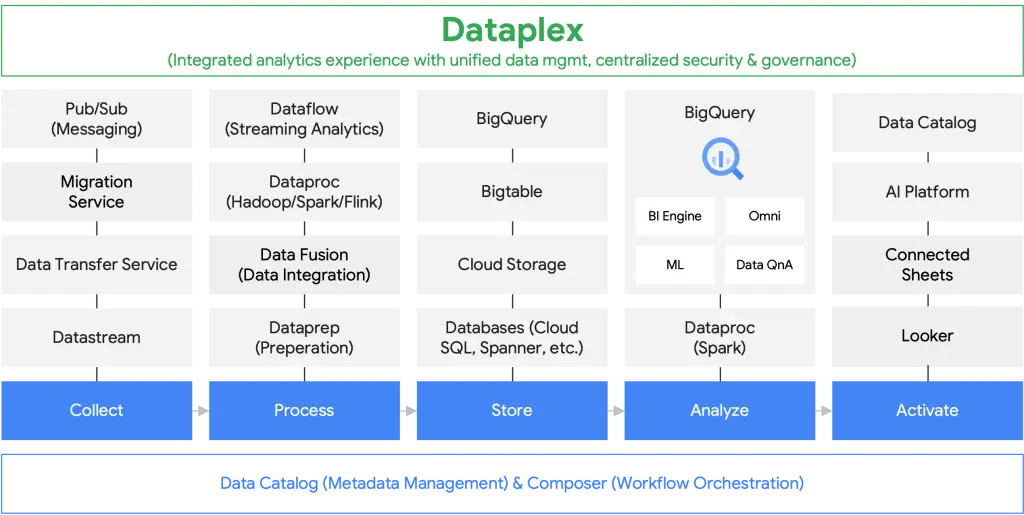
Data management and governance using GCP data mesh design
- GCP DataPlex for data stewards, data custodians, and data managers to develop data management policies and enforce governance
Data ingestion
- GCP Pub/Sub for real-time and event based asynchronous transactions
- GCP Firebase for real-time NoSQL database storage for mobile and edge data synchronization
Data storage
- GCP Cloud Storage for Blob data and unstructured files
- GCP BigTable for NoSQL structured and unstructured data storage
- GCP Spanner for globally available SQL structured/relational storage
- GCP FireStore for NoSQL document database storage
Data enrichment
- GCP Dataflow for real-time analytics and AI capabilities
- GCP Vertex AI for creating curated enriched datasets
Data processing and analytics
- GCP Dataproc for managed Apache Spark, Flink, and Presto capabilities
- GCP Vertex AI Workbench for managed end-to-end Jupyter notebooks to deploy ML models using TensorFlow and PyTorch
- GCP BigQuery for managed data warehousing with integrated ML and BI
- GCP AutoML for building image classifiers models and training ML models
- GCP JanusGraph on GKE with BigTable for modeling data entities and the relationships between them
- GCP DataBricks for managed collaborative workspace for data scientists
Data serving
- GCP Looker for semantic models and powerful BI visualizations
- GCP Data Studio for self-service BI and customizable charts and graphs
Data mesh OCI services
OCI data mesh design starts with GoldenGate real-time data mesh platform. Oracle has written much on data mesh design pattern and uses GoldenGate services to integrate with OCI and other cloud service providers data storage solutions. Oracle uses GoldenGate Veridata to validate and cleanse database replication issues while using Data Catalog for easy enterprise data search and discovery of data sources and datasets.
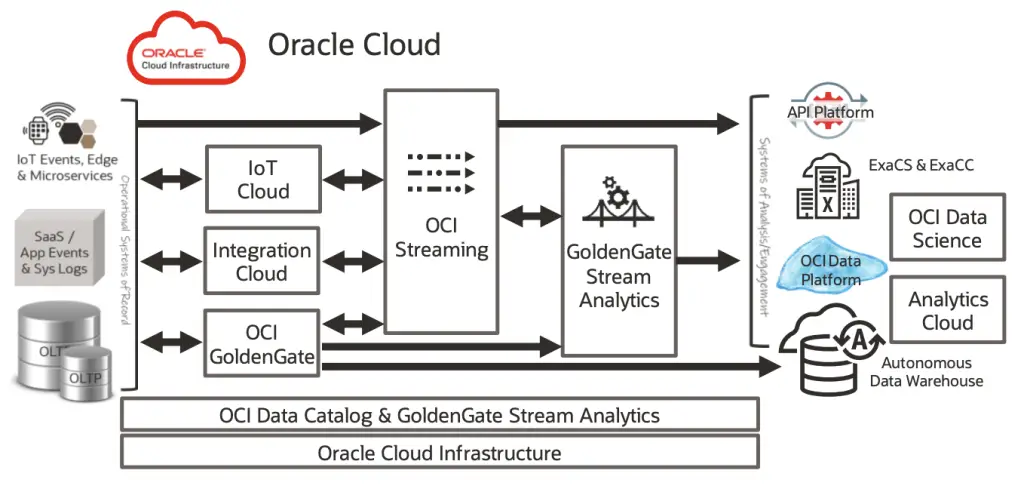
Data management & governance using OCI data mesh design
- OCI GoldenGate for data stewards, data custodians, and data managers to develop data management policies and enforce governance
- OCI Data Catalog for metadata management to search and discover
Data ingestion
- OCI Streaming for real-time and streaming data sources using Kafka
- OCI Queue for edge device data sources and event-driven microservices
Data storage
- OCI Object Storage for Blob data or any data type in native format
- OCI MySQL Heatwave for open-source relational databases
- OCI NoSQL Database for mixed structured and unstructured data stores
- OCI Big Data Service for managed Hadoop file systems
Data enrichment
- OCI Data Integrator for ETL of data into Oracle DB cloud services
Data processing and analytics
- OCI Stream Analytics for creation of custom analytics dashboards in Apache Spark -based systems
- OCI Autonomous Database for ML-tuned databases for analytic workloads
Data serving
- OCI GoldenGate for Big Data provides delivery to Hadoop, Kafka, and NoSQL databases and other cloud providers data storage solutions
NT Concepts specializes in designing data solutions and cloud management services for sensitive workloads. Working closely with AWS, Microsoft Azure, GGP, and OCI cloud service providers and account teams, we are a trusted government integration partner. We use our cloud expertise to design and build compliant, secure data management solutions for our federal, DoD, and Intelligence Community customers. Wherever your organization is with its data maturity assessment and DSIP, we can improve your data maturity and accelerate your digital transformation journey.
References:
1 Tekiner, F., Ha, T., Picard, J., Crowther, V., & Pierce, S. (2022). Build a modern, distributed Data Mesh with Google Cloud. Google. https://services.google.com/fh/files/misc/build-a-modern-distributed-datamesh-with-google-cloud-whitepaper.pdf
2 Z. Dehghani (2019). How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. MartinFowler.com. https://martinfowler.com/articles/data-monolith-to-mesh.html
