
As a Ph.D. computer and data scientist, systems and software engineer, applied statistician, and engineering fellow, I have worked on multiple large-scale Artificial Intelligence (AI) and Machine Learning (ML) projects for more than 30 years. Through that extensive experience, I have seen that creating solid AI and ML Project Design is similar in structure, process, and challenges to writing a good paper.
Much as a thesis forms the central argument of any paper, an ML model requires a clear purpose. This first quadrant of the ML Lifecycle is dedicated to formulating this thesis or purpose to design an ML solution that is appropriate for solving the challenge.
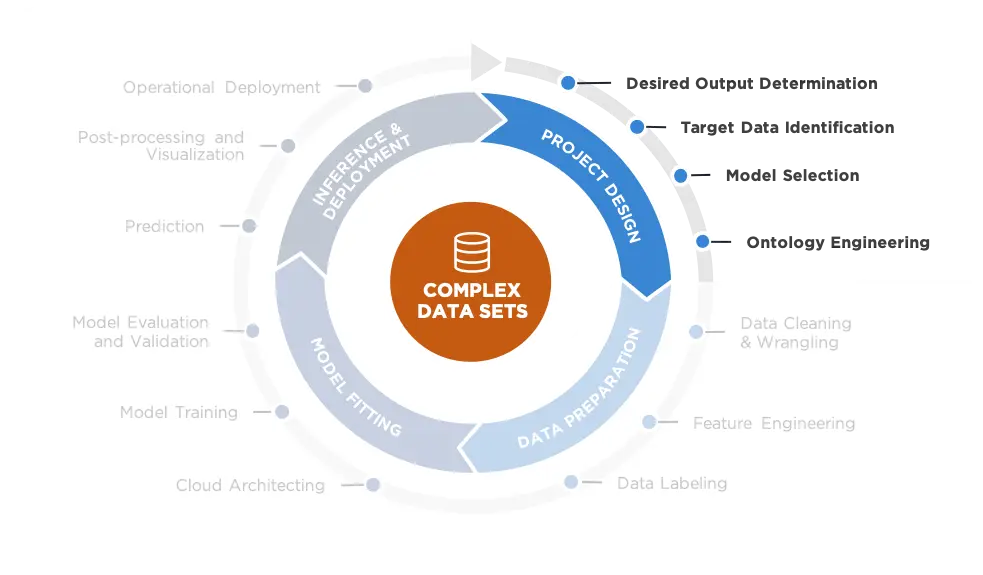
The complex nature of ML makes the Project Design phase perhaps the most challenging in the ML Lifecycle. After the data science team clarifies the automation or prediction need, they must determine whether the problem truly requires an ML solution. The solution is sometimes beholden to the data that are available to support it. Throughout the process, the team must continually assert that the algorithms are sufficient to answer the complex challenge at hand. They must also determine the most reasonable and reliable methods to train and customize the models for long-term success.
To address these challenges, the NT Concepts’ data science team engages a set of highly-structured sub-steps:
- Desired Output Determination
- Target Data Identification
- Model Selection
- Ontology Engineering
Step One: Determine Desired Output
The very first thing the data science team will do is to agree upon the desired output. What problem are you striving to solve? The first step in the ML lifecycle clarifies the problem or challenge that determines the objective output. The data science team will create a clear problem statement upon which they and the decision makers (customers) can agree.
Step Two: Identify Target Data
Step two goes hand in hand with step one because identifying your target data is dependent on clearly articulating the desired outputs. Once the problem statement has been accepted, the team can use the target data to survey existing works or algorithms that would work well as solutions. Herein lies an issue.
There is never enough labeled training data. There are two main options for solving this challenge—manual labeling and synthetic data labeling. Employing hundreds of data labelers to do the work can be cost prohibitive, and is prone to human error that can result in inaccuracies. Producing synthetic data labels may be less expensive and more accurate on the front end, but the option becomes problematic in the long run because machines tend to perform poorly on real-world tasks after training on synthetic data.
Step Three: Select the Model
Once the process has determined the desired outputs and necessary data, the data science team can evaluate whether a candidate solution or algorithm can address the problem. With so many models available, determining which of them to prioritize is a challenge. Ultimately, the team may decide that existing works or algorithms can solve part of the problem, but not all of it. They must then embark on selecting (or devising) a model that can fill in the gaps to do all the work necessary.
For example, for a large-scale biometric identification system, good evaluation criteria would include:
- Accuracy better than 99.5%
- Identification response time shorter than 10 seconds
- Capacity to search and identify an individual against a 100 million or larger population database
Because models are biased towards their inputs, a poor fit for the target dataset will result in inaccuracies. It is critical to know your models, know their origin (inclusive of their training sets), and know how their hyperparameters are tuned. Those assurances confirm what the model knows as well as how it ingests and processes the data.
Step Four: Engineer the Ontology
Through the process of identifying and selecting the project criteria, the data science team reaches a sense of how the experiment or project design should look. That determination includes how much and what types of data are required. The value of this step lies primarily in building an expectation about how well the candidate solution or algorithm is likely to perform against the collected training and testing datasets. The performance hypothesis uses selected criteria as the comparison matrix.
Presuming an appropriate model is selected, the team can begin to engineer the project ontology. This is the theoretical framework for the model that will identify, classify, and disambiguate the data. The target ontology reflects the properties and relationships between the data. It is informed by the goal and problem, as well as by the model(s) selected to process the inputs. This logic and taxonomy are critical for processing, monitoring, and measuring data as it expands in origin, scope, segmentation, and complexity. In short, the ontology tells the model what to look for and with what specificity.
What Comes Next
For organizations seeking to use ML to solve problems, success begins with asking the right questions, ensuring the quality of the data ingested, developing and selecting the appropriate ML models, and soundly structuring the taxonomy. Ensuring the accuracy and integrity of the project design can be constrained by the limitations of hardware and human resources, so the data science team may produce a Minimal Viable Model (MVM). The approach offers a lower-risk, higher-efficiency means of assessing and identifying which candidate solutions or algorithms provide the highest potential to produce the desired performance.
With that confirmation in place, the team can proceed with a more formal and complete scale test and evaluation. The team then can move into the second phase in the ML Lifecycle, during which the data is prepared and labeled. We will delve into this highly challenging aspect of the ML Lifecycle in the next post.